6 Photos From a Car, One 3D Scene: Best Student Paper at IEEE IV 2025
A self-driving car has six cameras on the roof: front, back, left, right, and two diagonals. Each camera sees a different slice of the world. Take a single snapshot from all six, and from just those six photos, reconstruct the entire 3D scene around the car. Buildings, roads, parked cars, trees, including the parts no camera directly saw.
6Img-to-3D does exactly this.
I worked on this at co-pace GmbH (part of Continental AG), together with Marius Kästingschäfers, Sebastian Bernhard, and Mathieu Salzmann from EPFL. We published it at IEEE IV 2025 (Intelligent Vehicles Symposium), where it won the Best Student Paper Award. Marius presented it in Cluj-Napoca on my behalf.

Why Is This Hard?
Most 3D reconstruction methods expect lots of overlapping photos, like walking around a statue and snapping 50 pictures from every angle. Every point gets seen by many cameras, so the math works out nicely.
Car cameras are the opposite. They point outward in different directions, so they barely overlap. Each one sees its own chunk of the world, and between them there are gaps, angles that no camera covers at all.

On top of that, driving scenes don’t have neat boundaries. The road stretches to the horizon, buildings go way up, the sky is infinitely far away. You can’t just put a box around the scene and call it a day.
How It Works
Take the six images, extract useful features from them using a neural network, combine those features into a compact 3D representation (three flat grids we call “triplanes”), and then use that representation to render the scene from any viewpoint, like a virtual camera you can place anywhere.
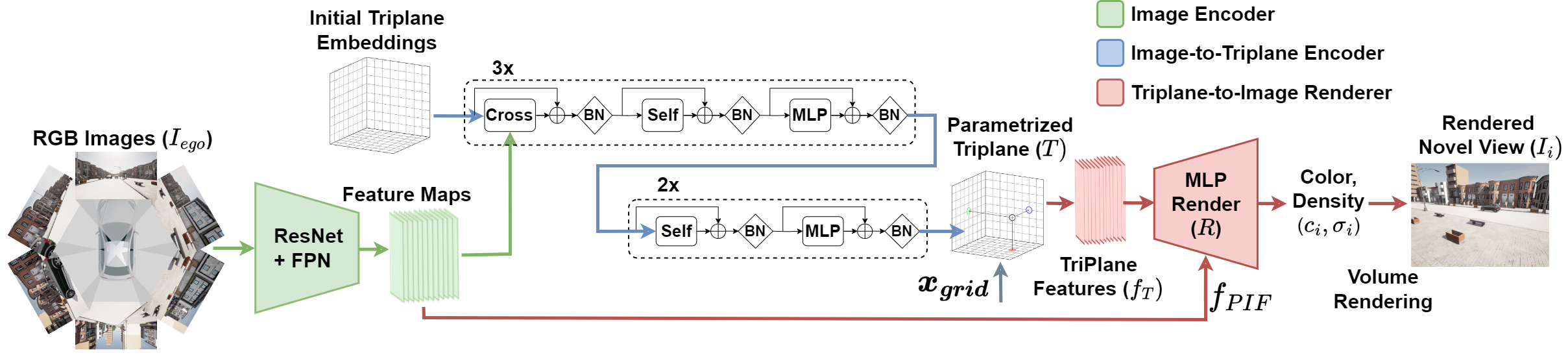
The interesting part is how the six images get turned into triplanes. We use a transformer (similar to what powers language models) that learns to look at the right parts of each image and piece together a coherent 3D understanding. It knows that the front camera’s left edge should connect to the front-left camera’s right edge, even though they barely overlap. It fills in the gaps using patterns it learned from thousands of training scenes.
To deal with the “infinite world” problem, we use coordinate contraction: a function that smoothly squeezes far-away content into a manageable space while keeping nearby details sharp. Getting this right turned out to matter more than many of the “interesting” architectural choices. Naive approaches (just clip at some distance, or use a huge bounding box) produce terrible results.
When rendering the final image, for each point in 3D space we also look back at the original photos and grab the actual pixel colors from there. This “projected image features” trick preserves fine details like text on signs or patterns on buildings that the 3D representation alone might blur out.
The Numbers
We trained on about 1,900 synthetic driving scenes from the CARLA simulator (more on that in the SEED4D post). The whole thing trains on a single GPU in about five days; some competing methods need eight high-end GPUs. Training on one GPU instead of eight isn’t just about saving money, it makes the research iteration cycle dramatically faster.
At test time, the model reconstructs a full 3D scene in under 400 milliseconds.
On the metrics that matter for image quality (PSNR, SSIM, LPIPS), 6Img-to-3D outperformed every baseline we compared against, including methods specifically designed for few-image reconstruction.
The paper is on arXiv and the code is open source at github.com/tgieruc/6Img-to-3D.
6Img-to-3D: Few-Image Large-Scale Outdoor Novel View Synthesis. Published at IEEE IV 2025. Best Student Paper Award.